
The Real Reason AI in Insurance Keeps Underdelivering Has Nothing to Do With the Technology


By early 2026, an estimated 80 percent of U.S. insurers had a generative AI solution in production. Investment in insurance AI has been sustained and significant: P&C insurtech funding alone surged to $1.13 billion in the first quarter of 2025, a 90 percent quarterly increase driven largely by AI innovation. Nearly 60 percent of carrier executives expect AI to significantly transform their business model within one to three years.
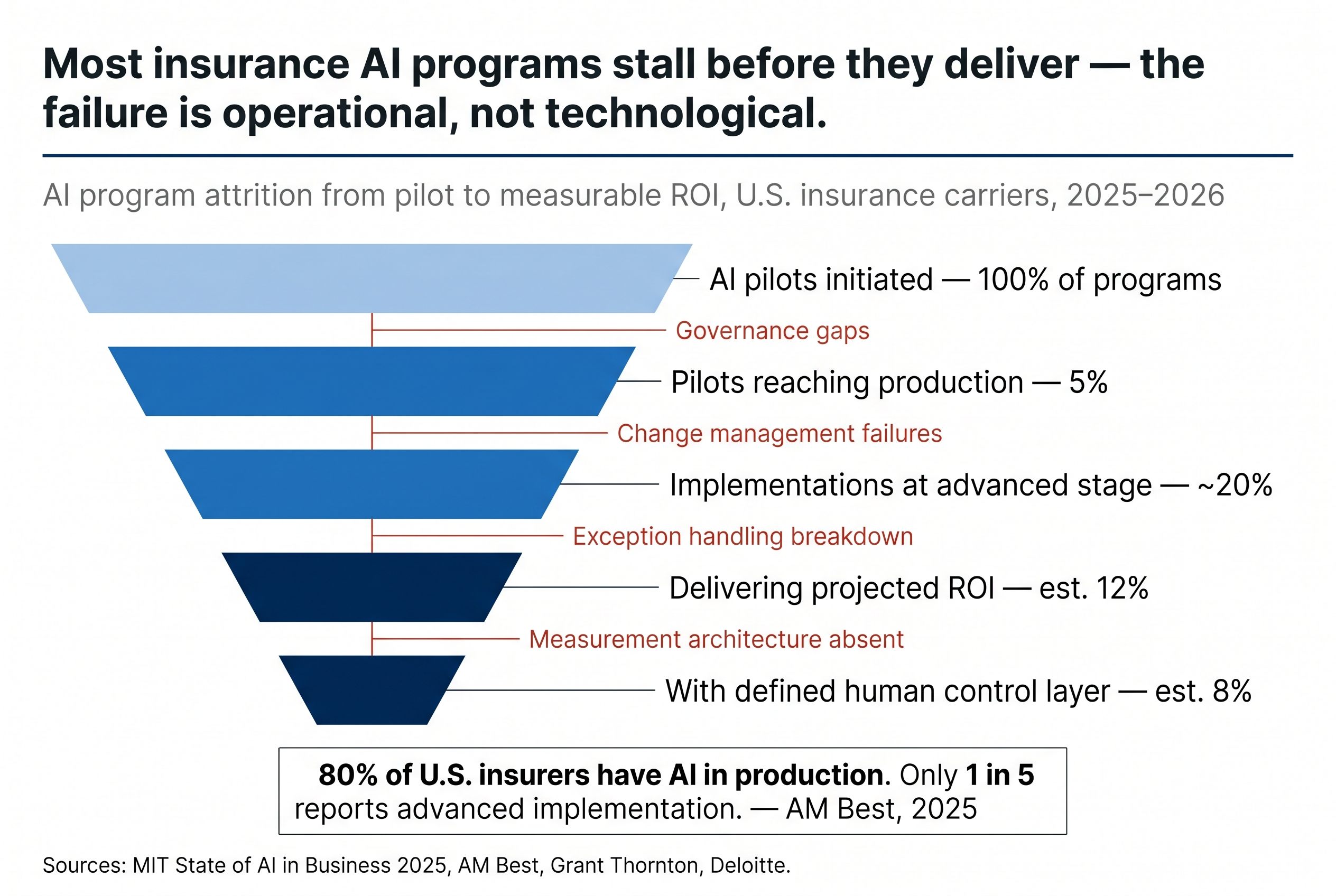
Against that backdrop of investment and expectation, the performance data tells a more complicated story. According to the MIT State of AI in Business 2025 report, 95 percent of generative AI pilots fail to reach production. AM Best's November 2025 survey of approximately 150 rated carriers and managing general agents found that only roughly one in five report their AI implementation is at an advanced stage. Grant Thornton's 2026 AI Impact Survey identified a persistent gap between AI adoption and measurable performance, describing governance as a "critical missing link" between investment and results.
The instinct in most organizations is to attribute underperformance to the technology. The model needs improvement. The data quality is insufficient. The integration is incomplete. These are real constraints in some cases. They are not, however, the primary explanation for why AI investments in insurance are consistently producing returns below expectation.
Deloitte's December 2025 research with 17 chief claims officers at leading P&C insurers found that adjuster skill gaps and change management, not technology availability, are the primary constraints on AI deployment. The technology is largely ready. The operational infrastructure to deploy it at production scale and manage it responsibly is, in most organizations, not.
What AI Actually Does Well in Insurance Operations
The conversation about AI in insurance has been distorted by both overclaiming and underclaiming, often within the same organization and sometimes within the same quarter.
On the overclaiming side: AI will transform underwriting, eliminate claims leakage, and replace the judgment of experienced professionals at a fraction of the cost. This framing drives investment decisions, creates unrealistic deployment timelines, and produces the disappointment that follows when production performance does not match pilot results.
On the underclaiming side: AI is not ready for insurance's complex regulatory environment, the edge cases are too numerous, and the liability exposure of automated decisions is too high. This framing drives delay, perpetuates manual processing costs that are entirely avoidable, and allows competitors who are deploying thoughtfully to build operational advantages that compound over time.
The accurate picture is more specific than either position. AI performs exceptionally well at a defined set of insurance tasks: document extraction and classification, structured data validation, fraud scoring, reserve recommendation on high-confidence cases, routine FNOL intake for simple claims, and image-based damage assessment. For these tasks, the evidence is consistent. AI-powered claims automation is delivering cost reductions of 30 to 40 percent per claim for standard cases. Cycle times for simple claims are falling dramatically. Accuracy on high-confidence, well-defined cases exceeds what manual processing historically achieved.
The problem is not that AI fails at these tasks. The problem is what happens at the boundary of these tasks, where the confidence score drops, where the case has characteristics the model was not trained for, where the regulatory requirement in a specific state demands a human determination rather than an algorithmic output, where the documentation is ambiguous, or where the claim has characteristics that experienced adjusters recognize as elevated litigation risk even when no single data point flags it conclusively.
That boundary is not a narrow edge of the claims population. It is a substantial and operationally significant portion of it.
The Exception Problem Is Larger Than Most AI Deployments Account For
The standard framing for AI in claims describes a clean separation: AI handles routine cases end-to-end, and humans handle exceptions. The operational reality is considerably more complex, and the gap between the framing and the reality is where AI investments lose most of their projected value.
The first dimension of complexity is the definition of routine. In a controlled pilot environment, with a carefully selected sample of claims, the proportion of cases that meet the AI system's confidence threshold for end-to-end processing looks compelling. In production, across the full diversity of an actual claims population, that proportion is consistently lower than pilots suggest. Cases arrive with missing documentation, ambiguous coverage questions, claimant communications that fall outside the model's training distribution, and regulatory requirements in specific states that introduce decision constraints the system was not built to handle. The exception rate in production is rarely what the pilot projected.
The second dimension is what happens to exceptions after they are flagged. Most AI deployments define an escalation path: cases below the confidence threshold route to human review. What most deployments do not define with equivalent precision is who reviews those cases, what information they receive, what the expected turnaround time is, what the quality standard for exception review looks like, and how the outcomes of exception reviews feed back into model improvement. Without that operational design, the exception queue becomes a black hole. Cases accumulate. Human reviewers, who were not staffed for the exception volume that production actually generates, manage the queue by processing it as quickly as possible rather than with the precision the cases warrant.
The result is AI that is technically deployed and operationally dysfunctional. The system is running. The outcomes are not improving. The investment thesis is not being realized. And the root cause is not the model. It is the absence of a human control layer designed with the same rigor as the AI layer it is supposed to supervise.
Grant Thornton's audit of one carrier's AI implementation identified precisely this pattern: gaps in output consistency, weaknesses in the human review process, and undocumented data-handling steps. These were not technology failures. They were operational design failures that the technology surface made visible.
Why the Human Control Layer Is the Actual Investment
The framing that most carrier AI programs operate under treats human oversight as a compliance requirement, a regulatory concession to regulators who are uncomfortable with fully automated decisions. Under that framing, the human control layer is a cost to be minimized as AI capability matures and regulatory tolerance increases.
That framing is strategically wrong, and the carriers that understand this are building material competitive advantages over those that do not.
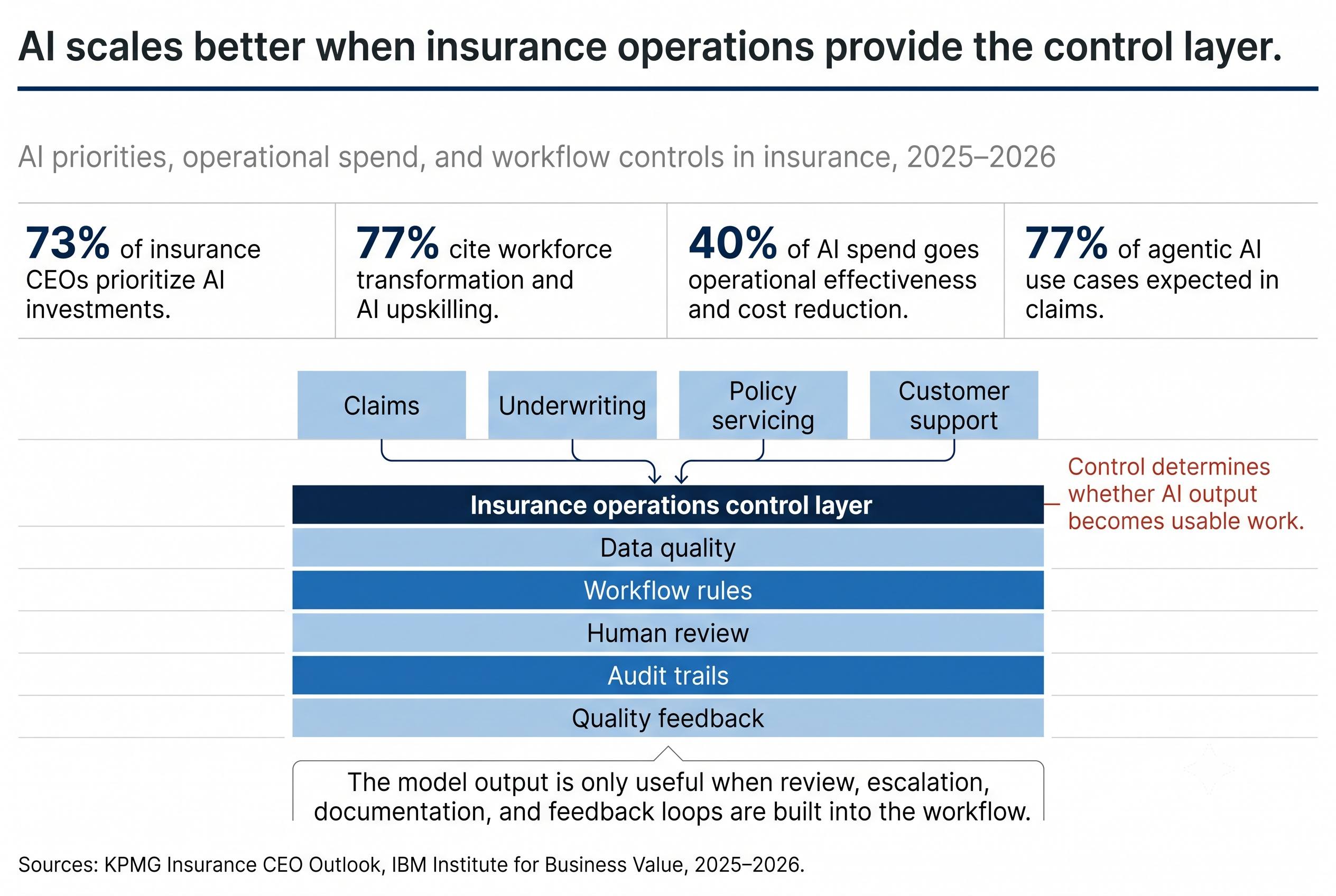
The human control layer in an AI-enabled insurance operation is not a transitional artifact waiting to be automated away. It is the mechanism through which the AI system produces outcomes that are consistently accurate, regulatorily defensible, and operationally trustworthy at scale. It is also the primary source of the feedback that improves the AI system over time. And it is the function that handles the cases where the consequences of error, in litigation exposure, regulatory penalty, or customer experience, are highest and most concentrated.
Insurance Thought Leadership's operational analysis of AI scaling programs described this precisely: human-in-the-loop AI is most effective when experienced insurance professionals are pulled into cases where their judgment adds the highest value in assessing complex risks, edge cases, and decisions with material financial or regulatory impact. The key word is experienced. A human review layer staffed with inexperienced personnel processing exceptions quickly to clear the queue is not a control layer. It is a throughput function that provides the appearance of oversight without its substance.
The operational design question that most carriers have not answered is: what does the human control layer actually need to look like to make this AI investment produce its projected outcomes? That question has specific answers across five dimensions.
The first is case routing precision. The AI system must route exceptions based on decision criteria that reflect the actual risk profile of the case, not simply the confidence score of the model. A case that falls below confidence threshold because of a documentation gap requires a different human response than a case that falls below threshold because it has characteristics that indicate elevated litigation exposure. Routing logic that treats all low-confidence cases identically misallocates human attention in ways that produce worse outcomes than the pilot projected.
The second is reviewer qualification matching. The cases that require human review in an AI-enabled claims operation are, by definition, the cases the AI could not confidently resolve. Those are typically the more complex, higher-stakes, and more judgment-intensive cases in the population. Routing them to reviewers with the shallowest insurance domain expertise produces outcomes that are worse than the cases warrant. The human control layer requires experienced insurance professionals, not general-purpose reviewers.
The third is feedback architecture. Every exception review should produce structured data that feeds back into the AI system's training and calibration. Organizations that treat exception reviews as dispositions, cases closed, rather than as signals, cases that reveal where the model's boundaries need adjustment, are forfeiting the compounding improvement that makes AI systems genuinely better over time rather than stable at their initial performance level.
The fourth is documentation discipline. Regulators examining AI-assisted decisions will request documentation of how exceptions were reviewed, what criteria governed the human determination, and how the outcome was recorded. The carriers that have built documentation standards into the exception review workflow from deployment rather than retrofitting them after a regulatory examination will manage that scrutiny materially better than those who have not.
The fifth is performance measurement architecture. AI ROI cannot be demonstrated without pre-AI baselines for cost per transaction, cycle time, and error rates, and it cannot be monitored without ongoing measurement against those baselines in production. The carriers that built measurement infrastructure before deployment can show their boards a credible ROI calculation. The carriers that did not are defending an AI program against perception-based skepticism with no objective evidence.
The Governance Gap Is Where AI Programs Either Compound or Stall
Grant Thornton's 2026 survey framed the industry's AI challenge with precision: governance is the critical missing link between AI adoption and measurable performance. For an industry built to manage risk, it is notable that carriers are taking unnecessary risks in their own AI adoption.
The carriers that will compound the value of their AI investments in 2026 and beyond are those that treat operational governance, the human control layer, the feedback architecture, the documentation discipline, and the performance measurement infrastructure, as the core of the AI program rather than as supporting scaffolding. The technology is available to all competitors. It is not a source of durable competitive advantage by itself. The operational model that deploys it with precision, manages its exceptions with expertise, and improves it continuously through structured feedback is the source of advantage. That model is harder to build and harder to replicate than the AI system it governs.
The 95 percent of AI pilots that fail to reach production are not failing because the technology does not work. They are failing because the operational infrastructure that makes the technology work at scale was not built alongside it.
The carriers that understand this are not asking whether to invest in AI. They invested. They are asking how to build the human operational infrastructure that makes that investment produce what they told their boards it would.
Related Blogs
Rethinking your
operations
doesn’t have to
happen alone.
If these challenges sound familiar,
let’s explore where your operations can improve.